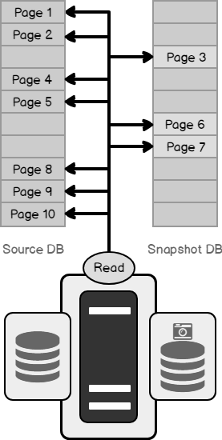
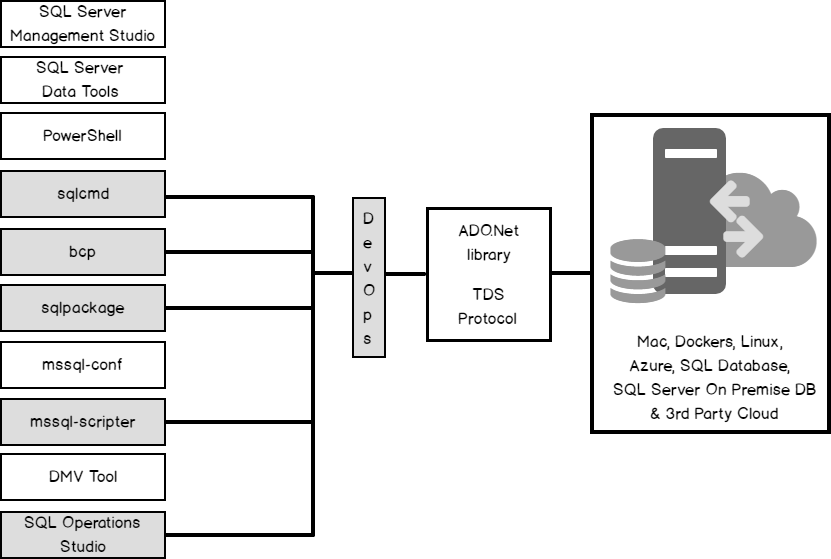
Data is the key to your organization’s future, but if it’s outdated, irrelevant, or hidden then it’s no good. Maintenance and administration of databases take a lot of work. As database administrators, we often tend to automate most of these repetitive tasks. A database refresh is one of the most common tasks performed by most of the administrators as part of their daily routine.
Today, database refreshes are quite frequent because of Continuous Integration (CI) and Continuous Deployment (CD). In most of the cases, testing requires a separate but current production dataset to ensure the validity of the desired result.
In today’s world, we rely more on third-party tools to perform a Backup and Restore of databases. With many advanced tools and techniques, this is a pretty straightforward approach. Think of the real-world scenarios where customers rely on the native SQL Tools and techniques. Creating automated database refresh tasks regularly will have a huge impact on the quality of the release management cycles and would save a lot of time for the database administrators.
There are many ways to automate this, some of which are:
- SQLCMD
- PowerShell
- SqlPackage
In this article, we about the following:
- Details of Sqlcmd
- The use of the cross-platform tool, Sqlpackage
- Automation using Windows batch scripting
- And more…
Using sqlcmd provides flexible ways to execute T-SQL and SQL script files. As its available on Linux, Windows, and Mac, this command line utility plays a vital role in managing the database restore operations in a DevOps pipeline.
PowerShell script to automatically create a bacpac file and restore the database using the created bacpac, using SqlPackage.exe
This section deals with the preparation of a PowerShell script to automate database restoration using the SqlPackage tool which is part of the SQL Server Data Tools suite.
The first step is to prepare and set the environment variables. The SqlPackage tool is installed under C:\Program Files (x86)\Microsoft SQL Server\140\DAC\bin. The script uses sqlcmd and SqlPackage tool; make sure that the path variable is updated accordingly.
- The input parameter section lists the source, target SQL databases instance and folder for extracting the bacpac file
- Create the bacpac file using export action type
- Select the latest bacpac file for further database restoration action
- Drop the destination database using the sqlcmd command
- Restore the database using import action type.
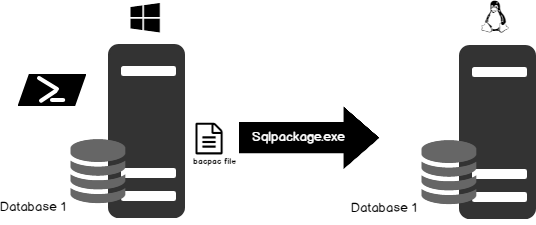
Continue reading sqlpackage
Happy Learning!