A detail paradigm to support SQL on Azure cloud, DP 300 study guide, and explore the hidden side of cloud databases.
Administering Relational Databases on Microsoft Azure takes readers through a complete tour of understanding of fundamental Azure concepts, Azure SQL administration, Azure Management tools and techniques. This book will give an edge over to clear DP 300 exam. Increasingly, we continue to be flooded with information about the importance of the cloud. Cloud computing is everywhere, but not everyone knows exactly what it is and where to get started.
This book audience is database professionals managing databases and interested in learning about administering the cloud data-platform technologies on Microsoft Azure.
This book is for those who are planning to become an Azure Database Administrator to manage the database infrastructure on the Azure relational data platform.
Azure database administrator exam serves as an ideal ThinkPad for furthering your understanding of database cloud computing solutions on Microsoft Azure. With this book, you can build your cloud expertise and gain technical competency to prepare for the Exam DP-300.
This book provides the reader with advanced Azure database management knowledge for Azure SQL Database, SQL on Azure VM, SQL Server, PostgreSQL, and MySQL. It delivers a solid understanding of Cloud infrastructure with detailed expertise in implementing Azure cloud database solutions.
This book aims to give a different dimension to face the DP 300: Administering-relational-databases-on-Microsoft-Azure. If you have been looking to move from On-Premise DBA to Cloud DBA, this book definitely helps you with all the required information. This book is an attempt to give enough information with detailed information on the Cloud infrastructure. This book covers the various areas of Administering databases on the Azure platform. In the end, you get to see many best practices based scenarios associated with cloud operations, useful links to Microsoft documentation, exam format and guide.
I have a very important announcement to make to all of you. Today on my birthday(16th March), I feel delighted and proud to announce the launch of my First book 𝐀𝐝𝐦𝐢𝐧𝐢𝐬𝐭𝐞𝐫𝐢𝐧𝐠 𝐑𝐞𝐥𝐚𝐭𝐢𝐨𝐧𝐚𝐥 𝐃𝐚𝐭𝐚𝐛𝐚𝐬𝐞𝐬 𝐨𝐧 𝐌𝐢𝐜𝐫𝐨𝐬𝐨𝐟𝐭 𝐒𝐐𝐋. It is available now for ORDERS.
This book is our experience, hands-on, scenario-driven, written with a purpose. We tried hard to get the best content and ensure to cover:
1.Know how to design database solutions for the Microsoft Azure platform 2. Understand the fundamentals to advanced concepts of SQL on Azure 3.Learn more about deploy, configure, monitor, and troubleshoot security, performance, and High Availability and Disaster Recovery scenarios in Azure SQL using advanced tools and techniques. 4. Automation workflow 5.Learn more about the Intelligent insight capabilities in Azure 6.Face DP 300 Azure Database Architect with confidence 7.Comprehensive SQL Server guide for Beginners and Intermediaries
I am excited to share an important milestone in my life. My third book, “Administering Relational Databases on Microsoft SQL“, is released. Co-authored with Ahmad Yaseen and Rajendra Gupta, who are known to be the databases’ best and bright minds in the database world. I am fortunate to work with Ahmad and Raj. It is never easy to craft a near perfection content, but we tried to bring in the best with our dedication and efforts.
I am dedicating this book to all the teachers, family, friends and SQL Shack team.
The content is based on our experience, hands-on, scenario-driven, written with a purpose—a comprehensive guide to becoming an SQL expert on Azure.
In today’s fast-paced, information overload world, efficient information is more critical than ever. There are so many complex questions to answer in the Cloud space of #Database and #cloud:
Why we have to shift from traditional DBA to Cloud DBA?
How can #organization get started their journey into the cloud?
What are the best methodologies and technique available for cloud adoption?
How to migrate from on-premise to cloud?
How to optimize the databases?
How to implement Automation?
How to configure HA and DR solution?
So, answer all unanswered questions more with the book “Administering Relational Databases on Microsoft SQL”. We tried hard to get the best content and ensure to cover:
Know how to design database solutions for the Microsoft Azure platform
Understand the fundamentals to advanced concepts of SQL on Azure
Learn how to administer SQL on Azure
Learn more about deploy, configure, monitor, and troubleshoot security, performance, and high availability and disaster recovery scenarios in Azure SQL using advanced tools and techniques.
Understand automation work-flow and design your first work-flow
Learn more about Intelligent insights and Analytics integration with PowerBI
A comprehensive guide, SQL on Azure for beginners
A quick refresher for experts
Practice 20 real-time scenarios
150+ Q&A to assess your readiness for the DP 300 exam
Face DP 300 Azure Database Architect exam with confidence
In India, order your paperback, using the following link
Please grab a copy and support!!. Please leave your reviews and help us promote and be a part of the greater initiative. I will be donating all my royalty to the Children’s Hospital of Wisconsin.
This book will help you and your colleagues have more productive discussions at work.
Ad hoc distributed queries use the OPENROWSET and OPENDATASOURCE functions to connect to remote data sources that use OLE DB. As the name suggests, ad-hoc distributed queries should only be used with infrequent access to data sources. For the datasources that has to be accessed frequently Linked server would be a better option.
An ad-hoc distributed query would look like this.
SELECT a.*
FROM OPENROWSET('SQLNCLI', 'Server=SQLinfo1;Trusted_Connection=yes;',
'SELECT Department, Name, DepartmentID
FROM AdventureWorks2012.HumanResources.Department
') AS a;
GO
By default, Microsoft turns off this option. However, we can enable the same using the below query.
exec sp_configure 'show advanced options', 1;
RECONFIGURE;
exec sp_configure 'Ad Hoc Distributed Queries', 1;
RECONFIGURE;
GO
The argument 1 at the end of the queries means ‘ON’, if you want to disable the ad-hoc distributed queries simply change the argument to 0.
exec sp_configure 'show advanced options', 1;
RECONFIGURE;
exec sp_configure 'Ad Hoc Distributed Queries', 0;
RECONFIGURE;
GO
In a strict and secured environment, we could see ad-hoc distributed queries referred to as a vulnerability and often turned off. However, some stored procedures may use this ability to reference OLEDB and pull data. Turning it off would cause the SP to fail.
SQL Statement to find the SPs using ad-hoc feature
The below T-SQL code can be used to check whether any stored procedures are using OPENROWSET,OPENDATASOURCE functions.
DECLARE @sql nvarchar(max);
SET @sql = '
select
@@SERVERNAME as ServerName,
DB_NAME() as DatabaseName,
Object_ID = (id),
OBJECT_NAME (id) as StoredProc,
Text
from syscomments
where text like ''%%OPENROWSET%%'' or text like ''%OPENDATASOURCE%''
';
CREATE TABLE #results (
[ServerName] [nvarchar](128) NULL,
[DatabaseName] [nvarchar](128) NULL,
[Object_ID] [int] NOT NULL,
[StoredProc] [nvarchar](128) NULL,
[Text] [nvarchar](4000) NULL
);
DECLARE @statement nvarchar(max);
SET @statement = (
SELECT 'EXEC ' + QUOTENAME(name) + '.sys.sp_executesql @sql; '
FROM sys.databases
WHERE DATABASEPROPERTY(name, 'IsSingleUser') = 0
AND HAS_DBACCESS(name) = 1
AND state_desc = 'ONLINE'
FOR XML PATH(''), TYPE
).value('.','nvarchar(max)');
INSERT #results
EXEC sp_executesql @statement, N'@sql nvarchar(max)', @sql;
SELECT *
FROM #results;
The output will show the SPs using the ad-hoc distributed queries option and we might have to look at the code and change it before disabling the ad-hoc distributed queries.
Using PowerShell to get data from multiple servers
By taking the help of PowerShell, we can run this query on multiple instances and return the output.
##Get the list of servers
$Servers = Get-content -path " your file path "
## for each loop to execute the code in given set of servers
$Servers|%{
$_
## T-SQL command
$cmd = "
DECLARE @sql nvarchar(max);
SET @sql = '
select
@@SERVERNAME as ServerName,
DB_NAME() as DatabaseName,
Object_ID = (id),
OBJECT_NAME (id) as StoredProc,
Text
from syscomments
where text like ''%%OPENROWSET%%'' or text like ''%OPENDATASOURCE%''
';
CREATE TABLE #results (
[ServerName] [nvarchar](128) NULL,
[DatabaseName] [nvarchar](128) NULL,
[Object_ID] [int] NOT NULL,
[StoredProc] [nvarchar](128) NULL,
[Text] [nvarchar](4000) NULL
);
DECLARE @statement nvarchar(max);
SET @statement = (
SELECT 'EXEC ' + QUOTENAME(name) + '.sys.sp_executesql @sql; '
FROM sys.databases
WHERE DATABASEPROPERTY(name, 'IsSingleUser') = 0
AND HAS_DBACCESS(name) = 1
AND state_desc = 'ONLINE'
FOR XML PATH(''), TYPE
).value('.','nvarchar(max)');
INSERT #results
EXEC sp_executesql @statement, N'@sql nvarchar(max)', @sql;
SELECT @@servername Servername,databasename,count(Object_ID) count,[StoredProc]
FROM #results
group by DatabaseName,Object_ID,[StoredProc]
having Object_ID>0
"
Invoke-Sqlcmd -ServerInstance $_ -Query $cmd | select * |Format-Table -AutoSize
}
The output of the code should be like:
Summary
Ad-hoc distributed queries can be termed as a critical vulnerability in secured environments. Consider other ways such as linked servers to get the data because they are a lot safer and robust.
The real-time data representation often requires quality content. In most cases, users flooded with multiple options or methodologies that may overwhelm the user to opt for the right techniques.
The quick notes from many geeks over the internet is a good start and at some instances, the conciseness of the article might meet our requirement; some other cases, it may direct with some pointers.
I believe that knowledge sharing is an effective method to grow with mutual terms. Over time, I realized how important to contribute and document the experience in a way to contribute to the communities.
This is an effort to recollect my 14 years of IT experience in the areas of data, data integration, data warehouse, and derive various data solutions through Hadoop eco-systems.
In this article, I will walk-through:
Discuss the pre-requisites
Migration from traditional data warehouse to Hadoop system
Tools and techniques
More…
Note:I touch-base some of tools or technology over period. In this series, I will walk-through Hadoop, HDFS, Sqoop, scala, python, Hive, Hbase, Spark2, mapreduce, kafka, flumes, Oozie, Unix, Shell, SSH, sql server, oracle, Teradata, informatica power center, Informatica Data Quality, Syncsort, Salseforce, Data bricks, Dremio, beeline, API, execution plan, spark physical joins, automation and best practices.
The enterprise data can be of structured, semi-structured, and unstructured data. In our case, we will consider structured and semi-structured data. To perform the data ingestion, we would need to build two types of the process;
Sqoop import for handling structured data; sources could be relational or delimited files
Spark streaming by reading a kafka topic
To start with, you can perform sqoop import using sqoop command from unix installed with a release of a hadoop installed. In order to support variety of sources like RDBMS, flat files and complex files you can build a framework with any of scripting or programming languages like shell scripting or advanced java based programs. With no bias decision will rely on the availability of resources and the amount of time you are ready to spend on building the reusable component and you are the right to one to decide what is right for you. In either case you will realize its benefits as short time versus long term respectively.
Here is the sample sqoop commands for relational source;
# sqoop import –connect “jdbc:oracle:thin:@<hostname:datasource>” –username BIGDATA_USER_T –password-file /user/tbdingd01/sqoop/BIGDATA_USER_T –query ‘select 1 from dual where $CONDITIONS’ -m1 –target-dir /tmp/kiran/test_ora.txt
Once the sqoop import runs successfully you can either create an externa table on hive with required table configurations or perform Hadoop file operations. By default sqoop imports file in text file format with comma as delimiter.
In the process of building a data product one would end-up applying many resource-intensive analytical operations on a medium to large data-set in an efficient way. Apache Spark is the bet in this scenario to perform faster job execution by caching data in memory and enabling parallelism in a distributed data environments.
Components involved in Spark implementation:
Initialize spark session using scala program
Ingest data from data lake through hive queries
Apply business logic using scala constructs or hive queries
Load data into HDFS or Hive targets
Execute spark programs through spark submit
We will learn the basics of implementation using Scala. Please refer this git branch click here
Let us see the simple spark submit and meaning of each configuration items
There are different ways to automate the data pipelines. In this section, we will see the required components to configure Oozie:
Sample Oozie property file
Sample Oozie workflow
Nodes in Oozie workflow
Starting Oozie Workflow
Note: As Oozie do not support spark2, we will try to Customize Oozie Workflow to support Spark2 and submit the workflow through SSH.
Please refer my git oozie sample branch for the xml and configuration files to build your oozie workflow. You can build the workflow using xml file or the oozie workflow manager through ambari url. Once you build the workflow, I prefer to validate once using workflow import from hdfs path. You should be able to see the workflow view as below as long as your workflow.xml file is valid.
The simple oozie workflow job submit will look as below:
0000123-19234432643631-oozie-oozi-W is the job id you can find it on the failed workflow on the oozie monitor info.
We have variety of ways to get things done, I have opted simplest way may be there are better ways to do build Hadoop data pipelines, enable logging and schedule the jobs. I have tried best to keep the scripts simple, clean and follow some basic standards for easier quality learning exchange.
If you find it interesting or wish to leave a comment, please feel free to provide your inputs to improve the quality of my content.
It is not unknown to the SQL users that some of the SQL Server versions have become outdated. This is the main reason why most of the SQL Server users are migrating SQL server database to Azure. Along with this, many are also moving to Azure due to its unique features. If you are switching the platform, you may also need to import local SQL Server database to Azure. In this post, we will discuss, two different approaches for the migration from on-premises SQL Server to Azure SQL database.
“Hello, all. I am writing here as I am in need to know the method to import data from SQL server to Azure. I have tried moving the database using the manual method, but that was unsuccessful as various issues came up. Please suggest me some effective method to perform this database migration smoothly and successfully.”
Techniques for Migrating SQL Server Database to Azure
There are different methods that will allow users to move their database to Azure. But not all of them are equally fruitful. To help our readers, we will talk about two methods in this post. One is manual and another one is automated. Let us not waste more time and go straight to the methods.
Manual Method to Import Local SQL Server Database to Azure
If users want to move their database manually, they can use the Deployment Wizard of SQL Server Management Studio (SSMS). This method should be used when the cloud migration process is not being hampered by any code compatibility problems. To start the migration in this method, run SQL Database Deployment Wizard on SSMS of any SQL Server instance.
Working Steps for migrating SQL server database to Azure
1. Select the database name from SSMS.
2. Right-click on it and select Tasks >> Deploy Database to Microsoft Azure SQL Database.
3. Fill in required Deployment Settings like Server connection, database name, the maximum size of the database, Azure SQL version, etc. Click Next.
4. Review the summary of the Settings and click on Finish.
5. Wait till the wizard finishes database validation, BACPAC file creation, and use Azure SQL for database creation.
6. When the process is completed, the new database has been created in the SQL Azure server.
Automated Method to Move Local SQL Database to Azure
If you think the manual method is time-consuming and requires a lot of attention, you can choose to use SQL Server to Azure Database Migrator Software. This application will allow you to seamlessly import local SQL Server database to Azure. Here are the complete working steps for the migration from on-premises SQL Server to Azure SQL database:
Step 1:Download and install the software on the Windows system.
Step 2: Launch the tool and click on the Open button.
Step 3: If the database is corrupt, choose Advance Scan mode. Otherwise, choose Quick Scan.
Step 4: Select the SQL Server version of the database. If you do not know the version, choose the Auto-detect option as pointing out the wrong version will cause trouble.
Step 5:For adding NDF file of the database, select NDF Options tab. Either manually select the NDF file or let the tool choose automatically. Make sure the NDF file is associated with the chosen MDF file.
Step 6: When file addition is done, users will be given a summary of the MDF file. If they want, they can also save the scan result for the future.
Step 7: Complete database records of MDF file including Tables, Triggers, Views, Stored Procedures, Keys, Indexes, Columns can be previewed. Click on Migrate button to import the database in Azure.
Step 8:Add Azure Database details and login credentials. Click on Connect and wait for the green tick mark.
Step 9:Select the destination database name from the list.
Step 10: On the left side of the tool, mark the database components you wish to move to Azure SQL Database.
Step 11: Also, select whether to transfer “With schema” or “With schema & data.” If required, users can also migrate deleted records.
Step 12:Click on Migrate and the software will successfully import local SQL Server database to Azure SQL Server database.
Final Words
Azure is gradually becoming a popular platform for SQL Database. Therefore, many people are migrating SQL server database to Azure. To meet their requirement, we have shared guidelines for two different techniques to perform this database migration. Users can go through the steps and choose that one they find useful. Since the software can import local SQL Server database to Azure in a short and simple manner, most of the users prefer this one over the manual method.
Maintaining the SQL server database is always the first priority of the SQL administrators. But sometimes SQL database users have to face Microsoft SQL server error 5243 and error 5242. These are common errors. Due to this problem, the SQL users won’t be able to access their databases. Let us understand the situation with the help of an example.
“Please help! I was working with my SQL database and doing some test. Everything was fine. But suddenly when checked my error log I received an error like this. Can anyone help me to fix this Microsoft SQL Server Error 5243? Thanks!
Msg 5242, Level 22, State 1, Line 1
An inconsistency was detected during an internal operation in database ‘Invoices'(ID:11) on the page (1:35397). Please contact technical support. Reference number 4.
SQL server introduced two errors types of errors 5243 or 5242. When the users receive this kind of error it means that the SQL server database is corrupt. This type of error is clearly visible in the error log. If this type of error occurs, then you then the user has to figure out what has happened to the I/O system. This error describes record type is wrong for the current type of page.
Methods to Fix Microsoft SQL Server Error 5243
Run the DBCC CHECK DB command – The user can try to run DBCC CHECKDB T-SQL command to restore the database. This command helps to check the physical and logical integrity of all the database objects in the specified database. For complete information about DBCC CHECKDB. If the database is too big then the user can use the REPAIR REBUILD option.
By Restoring The Corrupt Page – In case if the page is corrupt and if the user knows the corrupt page then it is possible to restore the correct page.
In Microsoft SQL Server Error 5243 the user can view the corrupted page. Also, the user can detect the corrupt page by using a select in the MSDB database to the suspect_pages table.
Follow this T-SQL command in order to restore the page
Restore Database < Your Database Name>
Page = File:Page
File <device_name >
WITH NORECOVERY
Resolve Microsoft SQL Server Error 5243 By Using Expert Solution
In case if the user cannot be able to restore the data then the user can use SQL Database Repair tool. With the help of this software, the user can easily fix Microsoft SQL Server Error 5243. This software is a simple, easy to use and smartly developed software. It can be used to restore SQL server database in case of database corruption. This utility can easily repair the corrupted MDF and NDF file data. By using this software the user can scan and recover triggers, stored procedure, functions, tables. Moreover, this tool is compatible with SQL server 2017 and its below versions.
Final Words
In this article, we have discussed how to fix Microsoft SQL server error 5243. The user can try to restore the database by using manual methods. But these methods require strong technical skills and knowledge. So to avoid data loss situation the user can take the help of MDF Recovery Software to resolve this problem.
Microsoft SQL server database contains the most crucial data of organizations. But while using MS SQL server many users often face problems like abrupt termination, database connection errors, transient errors, malicious software attacks. In order to save their important SQL server data, many organizations are prepared for the worst case scenarios to avoid data loss situations. In some situations, various users want to know how to restore SQL Server 2014 database from backup.
Well backing up your Microsoft SQL server data not only helps the user to restore the data but it also helps the user in such situations like disaster recovery. The general practice of creating the backup is very crucial when SQL data is the key factor for the business. Before proceeding to the solution part to restore SQL server 2014 database from backup. Let us first understand the importance of SQL server backups.
Importance of SQL Server Data Backups
Here are the points which help the user to understand the Importance of creating backups.
It helps to protect from power failures – As we know that computer systems are prone to damage due to power failures. So due to sudden power failures, the SQL data might get corrupt and it will lead to a data loss situation. Therefore with the help of backups, the user can easily restore the data.
Safety from Virus and other Malware attacks – Its nothing new that files and folder turn into an inaccessible state because of Virus and malware attacks. And by multiple trials of accessing the affected files and folders. The viruses spread throughout the system. So in this way backups helps to restore databases.
Recover data in case of Operating system failure – So in case of an operating system crash or failure, all the files and the data in the hard drive will be gone. Backing up the data is the only thing that remains in court to get things back.
Other Reasons – Data backup is also important in case if the general user’s errors like deleting a table by mistake. In that case, the user can easily restore the data from the backup.
Backing up the files and folders is not only essential things but also a good practice. That assures that your important data won’t go anywhere no matter how worse the situation is.
Restore SQL Server 2014 Database From Backup – By Using Manual Technique
#Technique 1: By Using SQL Server Management Studio
First, the user has to connect to the appropriate instance of the Microsoft SQL Server database engine.
After connecting, then go to the Object Explorer, and then click on the server name to Expand the server tree.
Now click on databases, and then choose either a system database or user database.
Perform the right click on the database and then go to Task and after a click on restore.
Choose the type of restoration operation. Such as database file, filegroups or transaction log.
Now on General page, the user has to click on from Device.
After that click on browse button to open the specify backup box dialogue box.
Now the user has to select the backup device in the backup media text box and after that click on Add button to open select backup device dialogue box.
Choose the device that you want to use for the restore operation. After selecting the restore option choose backup file and then click on OK.
Automated Solution to Restore SQL Server 2014 Database From Backup
The manual solution is not a reliable solution to perform this task. Because it requires strong technical knowledge. So to avoid in any data loss situation the user can take the help of SQL Backup Restore Tool. This software gives two export options SQL server database or SQL server compatible scripts to export SQL data. The user can easily recover and preview database Tables, views, stored procedure, Triggers, columns, functions, etc. This utility supports .bak file of SQL server 2017 and below versions.
Note: If the user wants to repair the corrupted MDF (primary database file) and NDF (secondary database file) then the user can try SQL database recovery software to resolve all the SQL database corruption issues.
Final Words
Many time SQL users want to know how to restore SQL server 2014 database from backup. So in this article, we have discussed the step by step procedure to perform this task. We have also given the importance of SQL server data backups. The above discussed manual solution to perform this task has various limitations. To avoid any data loss situations the user can take the help of Automated solution to resolve this issue.
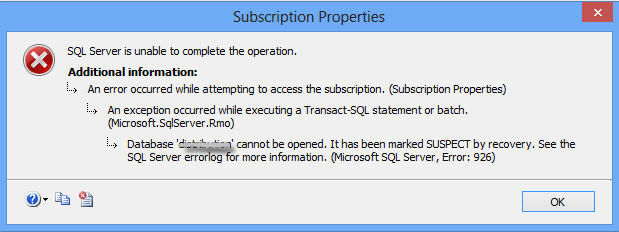
MS SQL server is a widely used relational database management system developed by Microsoft. It is a software product which primarily helps to store and retrieve the data of other applications. SQL database can have a specific state at a given time and it runs in various different modes which are online, offline, restoring, recovering, recovery pending, suspect, emergency. But sometimes when the user connects to the SQL server. The user will find the database is marked as a suspect state. The user will not be able to connect to the database. So in this article, we will discuss how to repair SQL database marked as suspect. Also, the forthcoming article will also discuss the various reasons for this error.
“I am currently using SQL server 2014 addition on my Windows 8 machine. Recently when I tried to connect to the SQL database I got an error like this database cannot be opened it has been marked suspect by recovery error. I don’t know what to do in this situation, Kindly guide me how to tackle with MS SQL database marked as suspect error problem.”
Possible Reasons Behind MS SQL Database Marked as Suspect
When the SQL server starts up, then it attempts to obtain an exclusive lock on the server device file. In case of the device, the file is being used by another program or its found missing then SQL server starts displaying errors. Here are the possible reasons for this problem.
Due to unexpected SQL server shutdown, power failure, or hardware failure.
In the case of a database, files are being held by the operating system or third-party backup software.
The system failed to open the device where the data or log files resides.
In case if the SQL cannot complete a rollback or roll forward operation.
SQL database cannot be opened due to inaccessible files or insufficient disk space.
Know How to Repair SQL Database Marked as Suspect – Manually
Here are the steps to fix MS SQL database marked as suspect mode problem.
First Open SQL server management studio and then connect to your database.
Now select the new query option.
Then turn on the suspect Flag on the database and then set it to Emergency
EXEC sp_resetstatus ‘database name’;
ALTER DATABASE databasename SET EMERGENCY
Now perform a Consistency check on the Master database.
DBCC CHECKDB (‘database name’)
Now Bring the database into single user mode and after that roll back the previous transactions.
ALTER DATABASE databasename SET SINGLE_USER WITH ROLLBACK IMMEDIATE
Take the backup of the complete SQL database.
Then attempt the database repair allowing some data loss.
Now refresh the server and verify the connectivity of the database.
Note: By performing the above steps the MS SQL database marked as the suspect problem will be solved. In case if the problem is still there then the user can take the help of an automated solution.
Automated Solution to Resolve MS SQL Database Marked as Suspect Error
If you have tried the above procedure and you are unable to resolve this issue or your database still marked as Suspect then you can try SQL Database Recovery. This utility is an ultimate solution to recover corrupted SQL database. By using this software the user can restore database objects like Triggers, views, functions, stored procedure, etc. This software is capable to recover deleted records from database tables. It provides two scan options which are quick scan and advanced scan to repair corrupted SQL database. This software is compatible with SQL 2017 and its below versions.
Final Conclusion
In this article, we have discussed how to repair SQL database marked as suspect. Also, we have discussed the various causes of this problem. We have given the manual solution to solve MS SQL database marked as suspect error issue. If the user doesn’t want to face any data loss situation then, in that case, the user can take the help of an automated solution MS SQL recovery tool to recover your most crucial SQL database.
Ease of use, accuracy, integrity, efficiency, and security are some characteristics which a good software should have, and when we speak of software products that focus on business users, the scale of expectations increases. Therefore, there remains no room for software functionality mistakes and bluffs; otherwise, the risk of data loss or corruption can surface.
Kernel Migrator for
SQL Server claims to migrate both corrupt and healthy SQL server database
file(s) to distinct cloud platforms, which I’ve tested carefully, to find out how well it gets the job done.
I’ll walk you through my Kernel Migrator for SQL Server
review dwelling the associated benefits
and my experience, explaining how well
the job of SQL Server database migration went.
Let’s have a look at specifications
first:
Supported Versions of
MS SQL Server: 2000 to 2017
Processor: Intel
Pentium.
RAM: 256 Minimum.
Storage: 50MB
For more info, you can visit
the Kernel website.
User Interface
Software should please you not only with its functionality but with looks as well; the User-Interface plays an important role in deciding the level of user acceptance & friendliness; otherwise, it’ll be like any other typical software product.
Kernel’s Migrator for SQL Server boasts of modern UI,
and if I compare with what it has to
offer, it doesn’t have multiple options which generally turns the look & feel
into bulky.
Open, Migrate, and Help are the main options available in the menu bar. Each time you launch the tool, the Select SQL Database window pops
on-screen automatically saving your time to reach to the Open option, but in case if you close the window you can reach
to the option and launch it again whenever needed.
My Experience
Support is
one of the important things which most of
the users seek from a software product whether it is for personal use or
business use. Kernel tool with its wide
support for older software versions eliminates the accessibility gap.
I’ve SQL Server 2017 installed on my system, and I was not hoping that Migrator for SQL
Server tool would be supporting this version, but
unexpectedly it did, and that’s not all,
the tool support all versions of SQL Server ranging from SQL Server 2000 to
2017 – which is the latest version of SQL Server available.
Kernel Migrator for SQL Server is accompanied with the built-in ability to detect the database
version, but in case if someone wants to select the same manually, he/she can
do so. For me, it did the job
automatically.
The
tool comes with the feature of Live Preview, which in all senses is
quite nice. Once you load the file and
the database file scan is complete, it lists all database objects in a tree
structure – you can expand or collapse the objects to check what’s inside and
click on the object to preview it.
For many, it can be
confusing for why does this feature even matter? It matters as it helps you in confirming
the data integrity & hierarchy.
For cross-check, I’d tried
a demo database file, and you all can see the results below.
At first, I thought of Kernel’s Migrator for SQL Server as a
simple tool that serves for the only purpose of database migration to Azure
SQL & Amazon RDS with limited functionalities, but after I used
it for a while, I was quite surprised to know that I can migrate either all or
selected database objects.
From
destination database selection to server
authentication credentials input, everything is combined and given in
unified Migration Options window; no extra efforts are required to first
configure the tool with SQL Server and login credentials.
Compatibility
The issue of compatibility sometimes comes as a big question
especially for those companies or
organizations who are still using an older build of SQL Server for their
database needs; there could be many
reasons why these organizations practice such habit.
Kernel has done a good job in terms of compatibility; the tool is made wide compatible with a range
of Microsoft SQL Server versions form SQL Server version 2000 to 2017.
Pricing & Availability
Kernel Migrator for SQL Server is made available in two
distinct product license categories which are Corporate and Technician License.
For both the license types, it offers lifetime support, software updates, and
100% money back guarantee.
The Corporate license costs
around $149 whereas Technician license costs for $299 including other
associated benefits. It’s not
proper to suggest you invest your money right after learning what I’ve
experienced, and so you can download the free version and check on your own.
The trial version is bounded with some limitations
but to prove the claims, it can generate Live preview of database objects.
Pros
Easy to use.
Minimal User-Interface.
Advanced Scan Mode.
Compatible with
older SQL Server versions.
Live Preview.
Cons
Cannot migrate database using the Free Trial
version.
Cannot select
more than one database file at a time for migration.
Summary
SQL
Migration tool is a lightweight tool that doesn’t require high-end hardware to run. It is easy to use too. In my Kernel Migrator
for SQL Server review, I’ve shared my experience to let you all better
understand how it performs the migration.
The free trial version allows you to understand
better about what you’ll be getting when you will make the purchase. You
too can share your views over the same and ask questions in case of any queries
you might have.
DB Technologist, Author, Blogger, Service Delivery Manager at CTS, Automation Expert, Technet WIKI Ninja, MVB and Powershell Geek
My Profile:
https://social.technet.microsoft.com/profile/prashanth jayaram/
http://www.sqlshack.com/author/prashanth/
http://codingsight.com/author/prashanthjayaram/
https://www.red-gate.com/simple-talk/author/prashanthjayaram/
http://www.sqlservercentral.com/blogs/powersql-by-prashanth-jayaram/
Connect Me:
Twitter @prashantjayaram
GMAIL powershellsql@gmail.com
The articles are published in:
http://www.ssas-info.com/analysis-services-articles/
http://db-pub.com/
http://www.sswug.org/sswugresearch/community/